Denne implementation er blevet lavet for at få nogle kompetencer til at kunne lave queries i en python applikation. Ved anvendelsen af pymongo biblioteket har vi oprettet forbindelse til en database i vores MongoDB cloud. Den indeholder så nogle collections og vi bruger en af collection til at fortage queries på.
Som kan ses på ovenstående billede importere vi biblioteker som pymongo og det bibliotek gøre at vi kan foretage interaktioner med vores MongoDB database via python. Det er en native Python driver til MongoDB
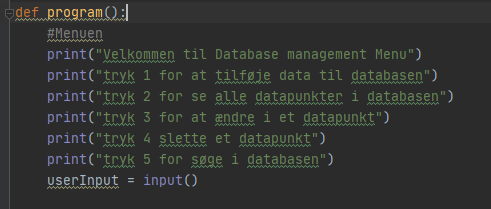
Derefter definere vi en funktion vi kalder program – det svarer til en metode der bliver kørt når programmes køres.
Når programmet køres så har vi 5 valgmuligheder vi kan vælge imellem:
Vi kan tilføje data til databasen
Vi kan se alle datapunkter i databasen
Vi kan ændre i databasen
Vi kan slette i databasen
Vi kan søge i databasen
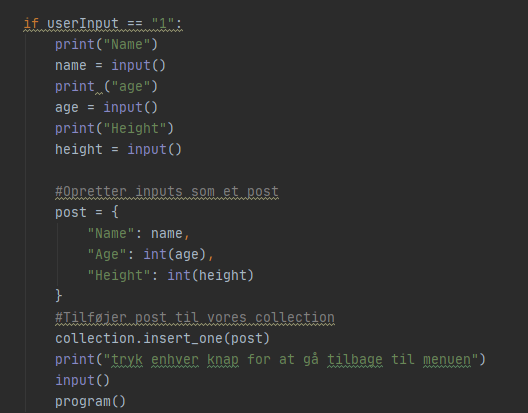
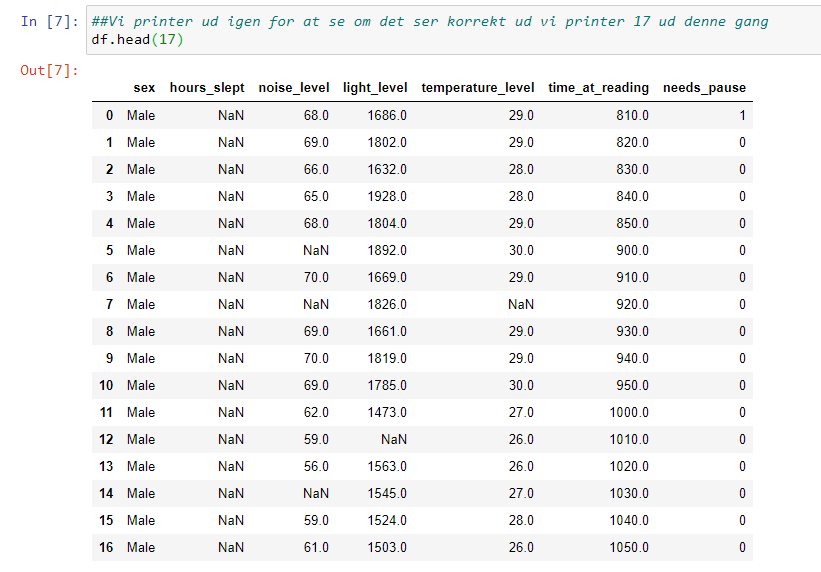
Hvis brugeren indtaster “1” i consollen kan personen tilføje et datapunkt i databasen. Dette er nogle af de inputs brugeren kan skrive: Name, Age, Height.
Vi definere efter en variable vi kalder post som indeholder de indtastede værdier.
Derefter kalder vi metoden “insert_one” som tager vores post variable som parameter. Det gøres på vores collection objekt.
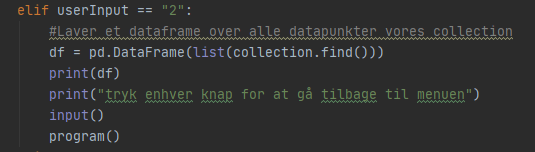
Hvis brugeren indtaster “2” i consollen kan vi få hele collectionen ud som et dataframe. Det bruger vi pandas biblioteket til. Vi definerer et dataframe variable som kalder metoden Dataframe i vores pandas objekt og laver en liste over hele collectionen som indeholder alle datapunkter. Derefter printer vi så resultatet for at se om collectionen bliver hentet korrekt ned.
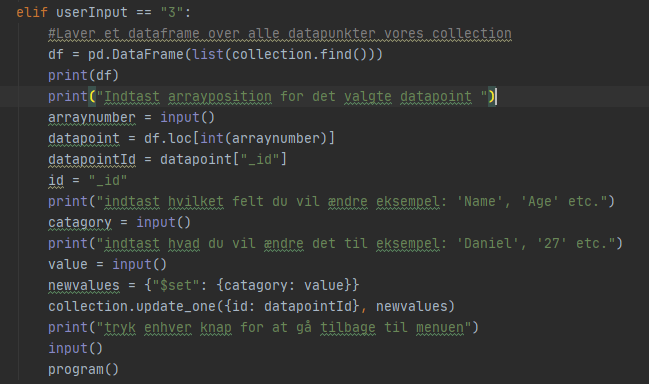
Hvis brugeren indtaster “3” i consollen kan brugeren ændre på et datapunkt i vores collection. det gøres ved at vi først henter hele vores collection ned. Så modtager vi et input fra brugeren som skal angive positionen på det datapunkt han gerne vil ændre i. Derefter bruger vi “loc” metoden på vores dataframe til at hente det specifikke datapunkt. Så indtaster brugeren hvilket parameter han gerne vil ændre i samt den nye værdi. Derefter anvender vi metoden “update_one” som så får id’en på det specifikke datapunkt samt de værdier han vil ændre på.
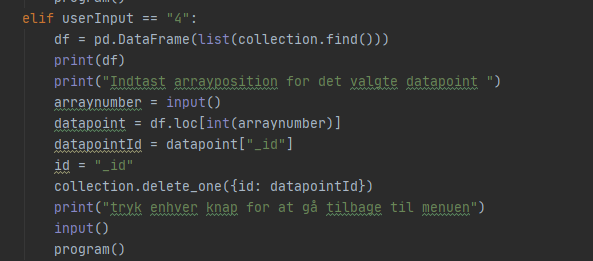
Indtaster brugeren “4” vil der være mulighed for at slette et specifikt datapunkt. Det gøres igen ved at angive index nummeret og derefter bruge metoden “delete_one” hvor den får id’et på datapunktet som argument
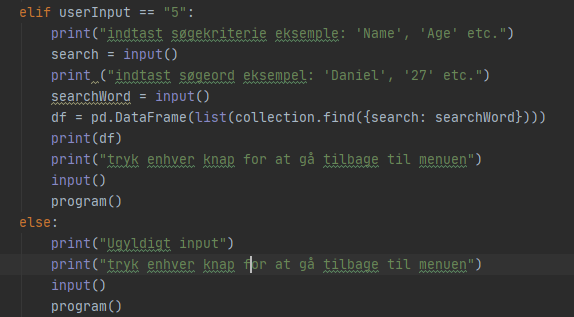
Indtaster brugeren “5” kan han søge i collectionen ved at angive et søgekriterie og derefter hvilken værdi personen søger efter. Den laver et dataframe hvor den laver en liste og den bruger metoden find i ens collection og den modtager parameteren for søgekriteriet man har oprettet.
Hvis man indtaster noget ugyldigt vendes der tilbage til menuen.
Dette er en simpel og grund forståelse for implementering af queries i python ved brug af en Dokument baseret database.
Specifikke læringsmål og læringsplan – 7.Iteration
Mål
Teknik/Værktøj
Kriterier
Evaluering
Anvende en databasegrænseflade til vores TV2 produkt projekt
Jeg vil gerne finde ude af hvordan jeg opretter en connection til MongoDB:
– Brug af erfagruppen til at diskutere måder på at kunne oprette en forbindelse.
– Søg efter viden på Youtube, Forums, Google og andre litteratur.
Kan jeg redegøre for hvordan jeg har implementeret min databasegrænseglade til min ERFA Gruppe og min produktgruppe samt diskutere relevante emner deromkring.
Jeg kunne præsentere for min projektgruppe samt nogle medlemmer fra erfagruppen ved et aftalt møde. Jeg kunne fremvise hvordan jeg integeret en databasegrænseflade i mit python projekt og opsætning osv.
Jeg vil gerne finde ude af hvordan jeg importere og eksportere data til og fra min databasegrænseflade:
– Brug af erfagruppen til at diskutere måder at gøre det på
– Anvendelse af Linkedin/Google/Youtube
– Netværk / venner / bekendte
Arbejde med et datasæt som er relevant for vores Produkt
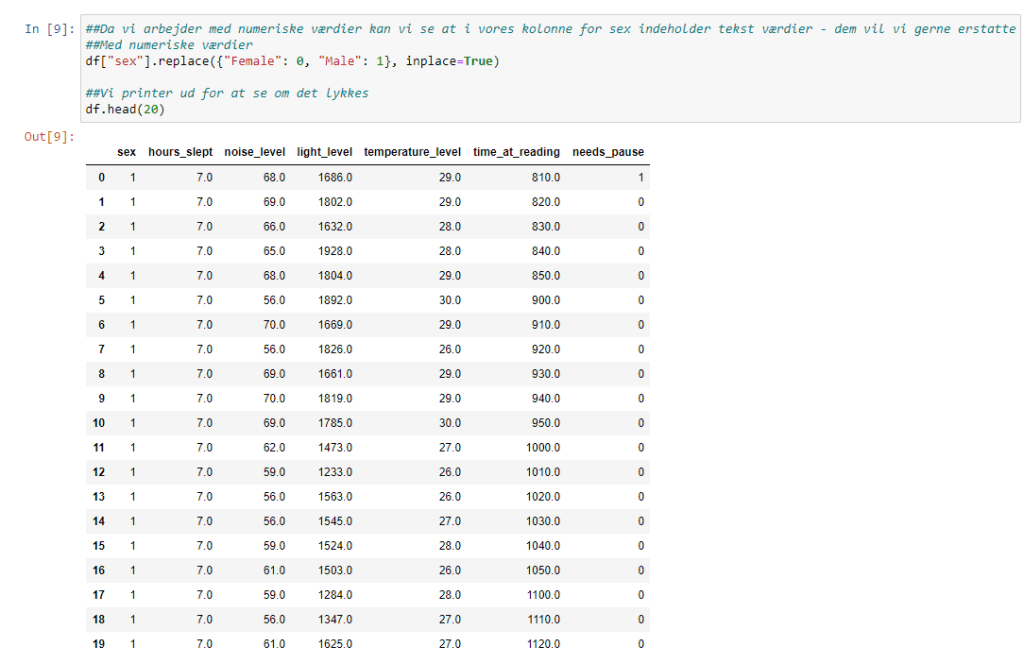
Jeg inspecter datasættet, for at finde ude af om der er nogle problematikker som skal løses før vi kan udføre vores machine learnings algoritme (herunder missing values, non numerical og overflødige features:
– Jeg anvender pandas biblioteket til at læse datasættet
– Jeg anvender Python Programmering til at udskrive et læsbart datasæt
– Jeg anvender Numpy biblioteket til at fikse de steder hvor der er missing values
– Jeg anvender scikitlearn Biblioteket til at ændre non-numerical features til numerical features
– Jeg anvender pandas biblioteket til at fjerne ikke-relevante features
– Bruger linkedin/Youtube for at finde video omkring emnet
– Anvender litteratur herunder Bøger omkring emnet
Kan jeg fremvise mit datasæt for min erfa gruppe?
Kan jeg redegøre for de ædnringer der er blevet foretaget undervejs?
Jeg har kunne anvende værktøjer til at behandle mit datasæt således at kriterier opfyldes for hvornår og hvordan man bedst muligt kan optimere sit datasæt til sin given machine learnings algoritme
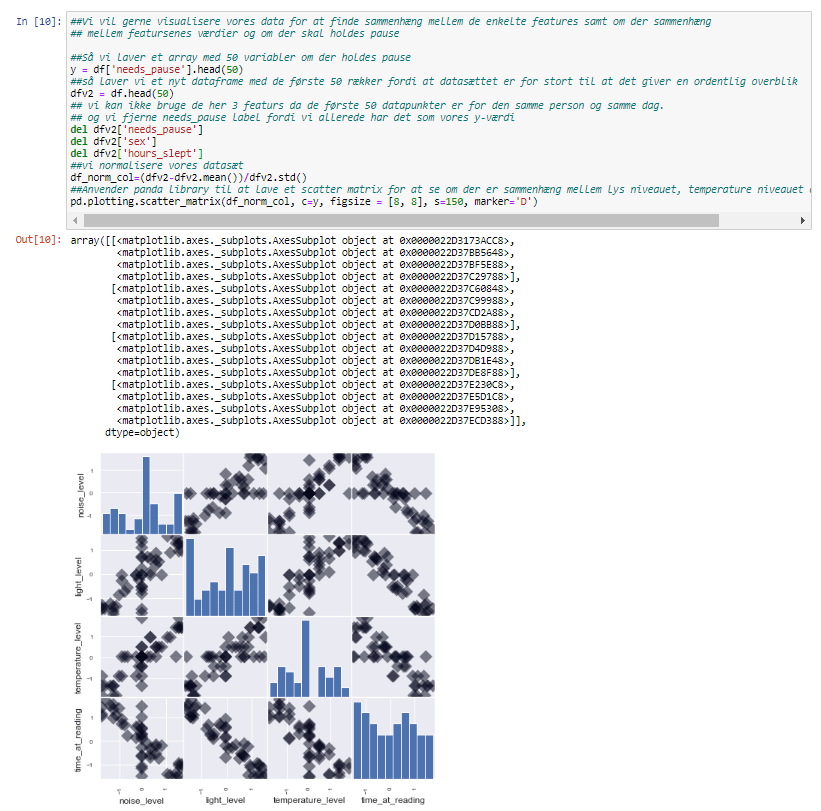
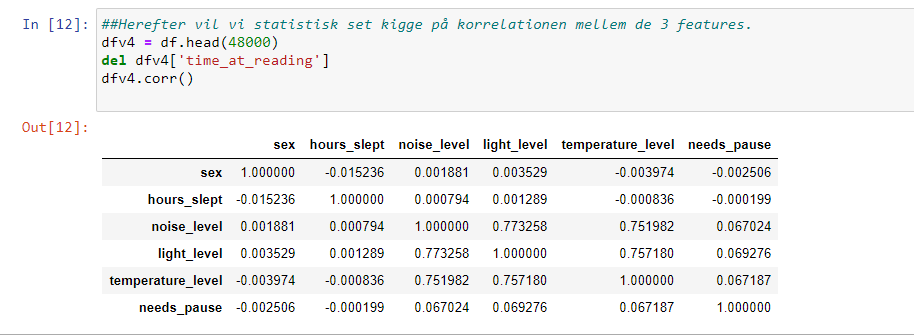
Jeg vil gerne visualisere mit datasæt så jeg kan analaysere om der er korrelation mellem features:
– Jeg anvender biblioteker som Pandas, Plotly, Matplotlib
– Jeg anvender google for at finde artikler omkring emnet
– Bruger netværk herunder ERFA grupper/Bekendte
– Bruger linkedin/Youtube for at finde video omkring emnet
Jeg vil gerne implementere den machine learnings algoritme jeg har valgt til mit TV2 produkt projekt
Jeg træffer en professional beslutning omkring den valgte agoritme:
– Jeg anvender den viden jeg har fået gennem arbejdsprocessen
– Jeg anvender google for at finde artikler omkring emnet
– Bruger netværk herunder ERFA grupper/Bekendte
– Bruger linkedin/Youtube for at finde video omkring emnet
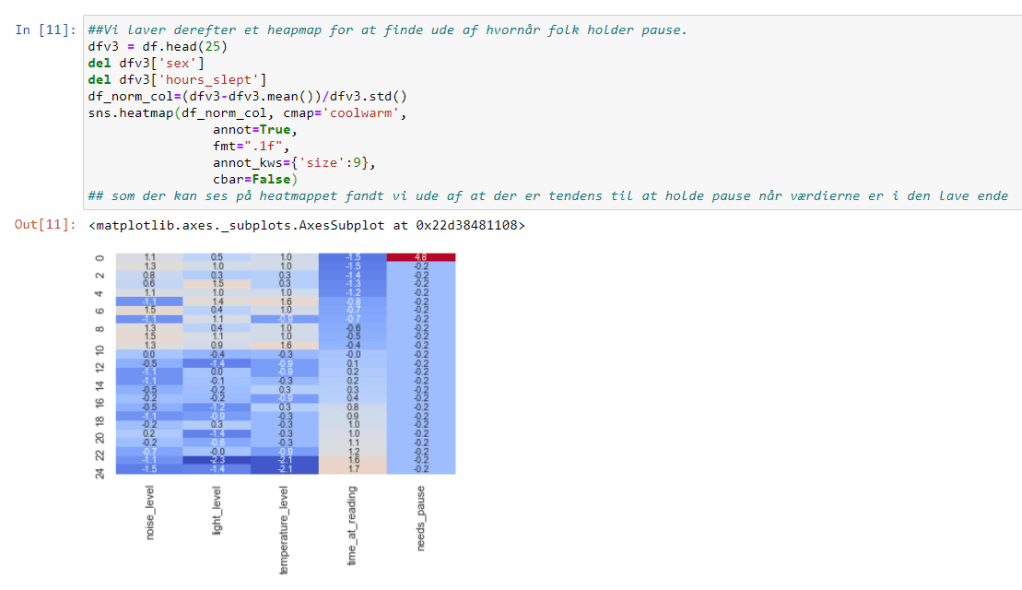
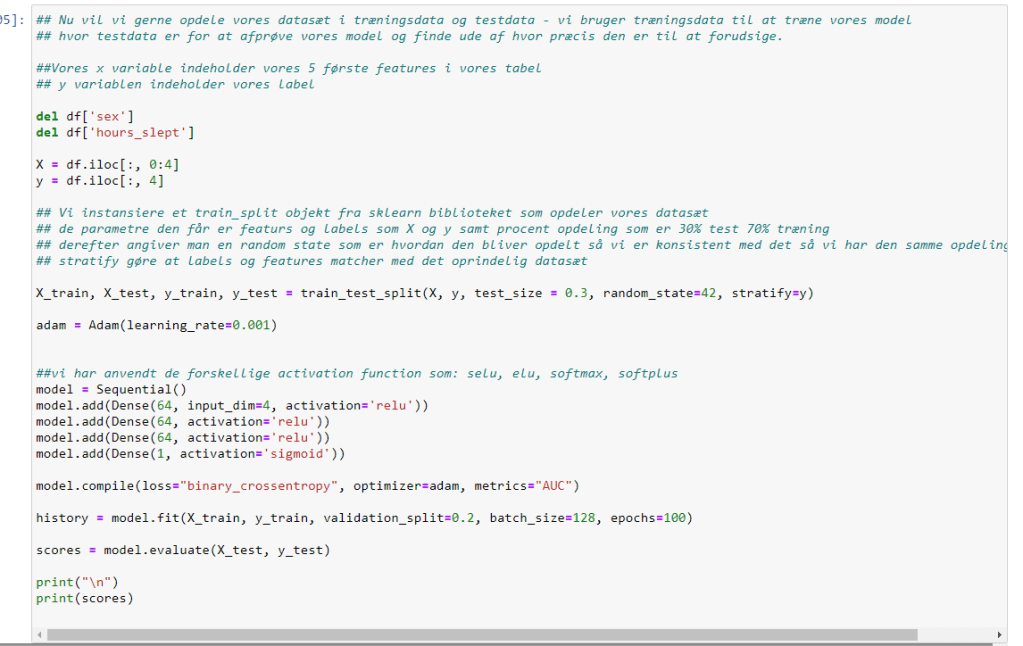
Anvende Neural Network algoritme for at finde ude af hvornår det bedst at holde pause:
– Anvender tensorflow og keras samt pandas biblioteker for at bruge værktøjer til algoritmen
– Jeg anvender google for at finde artikler omkring emnet
– Bruger netværk herunder ERFA grupper/Bekendte
– Bruger linkedin/Youtube for at finde video omkring emnet
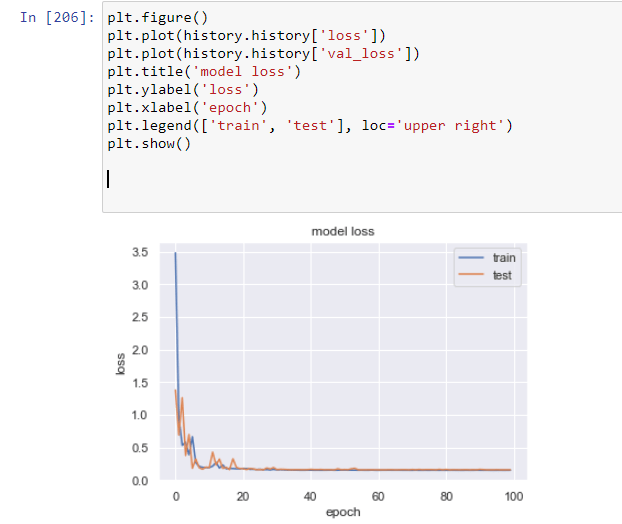
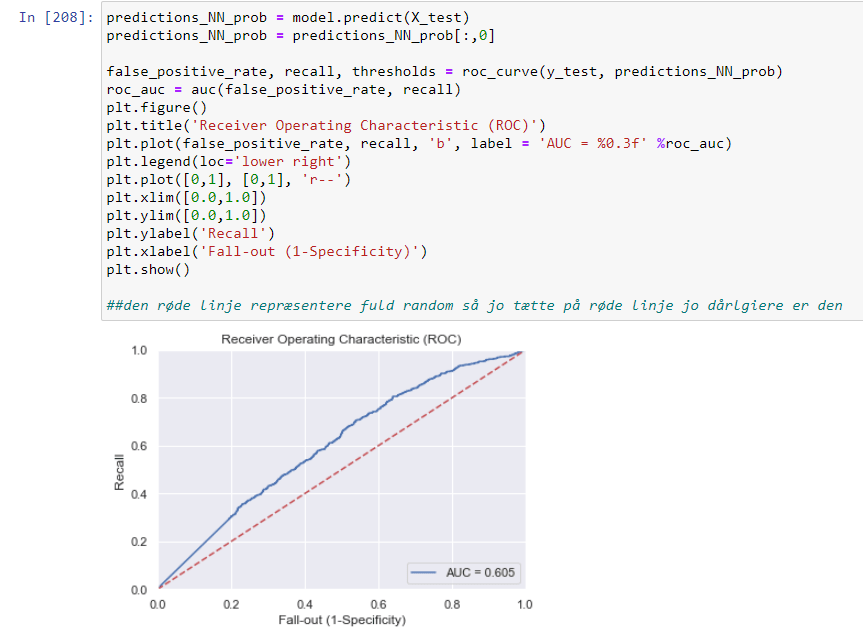
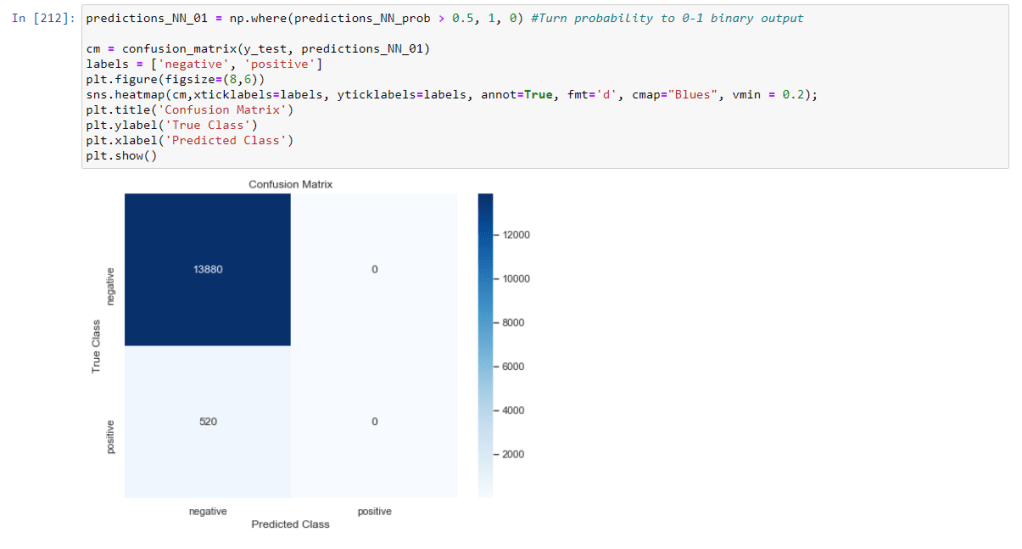
Er modellen præcis og kan den forudse om der skal holdes pause eller ej udefra et datasæt
Det er ikke muligt for modellen at forudse hvornår der skal holdes pause. Den ender med at angive at der skal holdes pause konstant – starts udgangspunktet var vores model var ligeså dårlig som at slå med en terning. dog fik vi forbedret den en smule men ikke nok til at man kan vurdere den brugebart. Grunden til dette er fordi at det datasæt vi har er random generet ved brug af c# program som lavede et datasæt til os. Det var alt for randomized til at det var brugebart.
Generelle læringsmål
Viden – Den studerende har viden om
Det/de valgte emners teori og praksis
Det/de valgte emners relevans i forhold til IT-fagets teori og praksis
Færdigheder – Den studerende kan
Udvælge, beskrive og foretage litteratursøgning af en selvvalgt it-faglig pro-blemstilling
Diskutere samfundsmæssige aspekter knyttet til det/de valgte emner
Vurdere problemstillinger og opstille løsningsmuligheder i forhold til det/de valgte emner
Formidle centrale resultater
Kompetencer – Den studerende kan
Selvstændigt sætte sig ind i nye emner inden for fagområdets teori og/eller praksis
Perspektivere og relatere det/de valgte emner i forhold til uddannelsens øv-rige emneområder
Specifikke læringsmål og læringsplan – 6.Iteration
Mål
Teknik/Værktøj
Kriterier
Evaluering
Anvende keras bibliotek til at udføre et projekt i neural netværk
Jeg vil gerne finde ude af hvordan jeg anvender keras biblioteket i et neuralt netværk:
– Brug af erfagruppen til at diskutere teknikker og værktøjer man kan bruge til et neuralt netværk
– Søg efter viden på Youtube, Forums, Google og andre litteratur.
Kan jeg redegøre for hvordan jeg har implementeret et neuralt netværk med keras biblioteket til mit projekt til min ERFA Gruppe og min produktgruppe samt diskutere relevante emner deromkring.
grundet af helligdag var det ikke muligt at fremvise det til erfa gruppen men jeg fik lov til at fremvise til produktvejledning samt brugt det til præsentation til procesvejledning.
Arbejde med mongodb Som dokument baseret NOSQL database
Jeg vil gerne få en forståelse for document database så jeg har mulighed for at vurdere hvilken database der er mest optimalt for mit projekt:
– Bruger linkedin/Youtube for at finde video omkring emnet
– Anvender litteratur herunder Bøger omkring emnet
Jeg vil gerne finde ude af at implementere en document database som et selvstændigt projekt:
– Bruger linkedin/Youtube for at finde video omkring emnet
– Bruge erfa gruppen
– Bruge andre sociale medier – herunder forums som quora
– Anvende diverse tutorials der findes på nettet
Kan jeg argumentere for enten at vælge eller fravælge document database i mit projekt samt fremvise min database til min erfagruppe og produktgruppe?
Efter at have fået en god forståelse for anvendelsen af document database har jeg kunne taget en professionel beslutning om at bruge det til mit produkt projekt. Samt har jeg kunne fremvise min database og fået feedback i min erfa gruppe.
Generelle læringsmål
Viden – Den studerende har viden om
Det/de valgte emners teori og praksis
Det/de valgte emners relevans i forhold til IT-fagets teori og praksis
Færdigheder – Den studerende kan
Udvælge, beskrive og foretage litteratursøgning af en selvvalgt it-faglig pro-blemstilling
Diskutere samfundsmæssige aspekter knyttet til det/de valgte emner
Vurdere problemstillinger og opstille løsningsmuligheder i forhold til det/de valgte emner
Formidle centrale resultater
Kompetencer – Den studerende kan
Selvstændigt sætte sig ind i nye emner inden for fagområdets teori og/eller praksis
Perspektivere og relatere det/de valgte emner i forhold til uddannelsens øv-rige emneområder
Specifikke læringsmål og læringsplan – 5.Iteration
Mål
Teknik/Værktøj
Kriterier
Evaluering
Anvende Neuralt netværk algoritme til et projekt
Jeg vil gerne finde ude af hvordan jeg anvender et neuralt netværk:
– Brug af erfagruppen til at diskutere teknikker og værktøjer man kan bruge til et neuralt netværk
– Søg efter viden på Youtube, Forums, Google og andre litteratur.
Kan jeg redegøre for hvordan jeg har implementeret et neuralt netværk projekt til min ERFA Gruppe og min produktgruppe samt diskutere relevante emner deromkring.
det er gået rigtig godt med at præsentere det både for min produktvejleder, min erfagruppe og min projektgruppe. Jeg har kunne fremvist og forklaret de forskellige metoder der er indenfor neurale netværk samt fået en god grundforståelse for hvordan det bliver opsat.
Arbejde med en key value pair nosql database
Jeg vil gerne få en forståelse for key value pair database så jeg har mulighed for at vurdere hvilken database der er mest optimalt for mit projekt:
– Bruger linkedin/Youtube for at finde video omkring emnet
– Anvender litteratur herunder Bøger omkring emnet
Jeg vil gerne finde ude af at implementere en key value pair database som et selvstændigt projekt:
– Bruger linkedin/Youtube for at finde video omkring emnet
– Bruge erfa gruppen
– Bruge andre sociale medier – herunder forums som quora
– Anvende diverse tutorials der findes på nettet
Kan jeg argumentere for enten at vælge eller fravælge keyvalue pair database i mit projekt samt fremvise min database til min erfagruppe og produktgruppe?
Efter at have fået en god forståelse for anvendelsen af key value pair database har jeg kunne taget en professionel beslutning om valget af typen af nosql database i mit produkt projekt. Samt har jeg kunne fremvise min database og fået feedback i min erfa gruppe.
Generelle læringsmål
Viden – Den studerende har viden om
Det/de valgte emners teori og praksis
Det/de valgte emners relevans i forhold til IT-fagets teori og praksis
Færdigheder – Den studerende kan
Udvælge, beskrive og foretage litteratursøgning af en selvvalgt it-faglig pro-blemstilling
Diskutere samfundsmæssige aspekter knyttet til det/de valgte emner
Vurdere problemstillinger og opstille løsningsmuligheder i forhold til det/de valgte emner
Formidle centrale resultater
Kompetencer – Den studerende kan
Selvstændigt sætte sig ind i nye emner inden for fagområdets teori og/eller praksis
Perspektivere og relatere det/de valgte emner i forhold til uddannelsens øv-rige emneområder
Som du kan se i min tidligere post har jeg arbejdet med et projekt til league of legends hvor jeg bruger et Neuralt netværk til at bedømmet hvorvidst en person har spillet godt eller dårligt. I den udgave er det hele meget manuelt hvor jeg selv har defineret vores algoritme samt det neurale netværk og hvordan det lærer, vil jeg her bruge Keras biblioteket til at udfører den samme opgave, men gøre det på en mere simplificeret måde hvor det er nemt at foretage ændringer i det neurale netværk, så det er nemt at finde den bedste måde for netværket at trænes på.
Først gemmer vi vores datasæt som et numpy array
Her har jeg været nødt til at ændre nogle værdier da den algoritme jeg bruger i vores neurale netværk har svært ved at håndtere alt for store tal som gør at den ikke har mulighed for den at forbedre sig. i dette tilfælde har jeg ændret tallene for hvor meget skade folk har lavet fra f.eks. 7299 til 7.229.
Derefter inddeler vi vores datasæt i X værdier (features) og y værdier (labels)
Her kan det ses at jeg sætte de første 8 værdier til at være vores X værdier og vores sidste værdi til at være vores y værdier
derefter skal jeg så til at lave det neurale netværk, det gøres først ved at instansiere sequential objektet og lægge den i en variabel “model”
Sequantial klassen indeholder som er en del af keras biblioteket anvendes til at danne layers
i ens neural netværk.
derefter tilføjes der så Layers til det neurale netværk ved brug af model.add funktionen. Her bliver der tilføljet et Dense layer, det betyder et fully connected layer. Den første værdi bestemmer hvor mange hidden units layeret skal bestå af, derefter skal man ved det første layer angive input dimensionen, hvilket i dette tilfælde er 8 da vi har 8 forskellige features i vores datasæt, til sidst angiver vi aktiverings funktionen relu. I et neuralt netværk er en aktiverings funktion ansvarlig for at transformere summen af weighted input fra node til aktiviteten af en node eller output for en specifik input. RELU -> Rectified linear activation function er en lineær funktion som vil output selve inputtet direkte hvis den er positiv ellers vil den outputte 0. Det er en default aktiverings funktion for mange typer af neurale netværk fordi en model som bruger lige netop dette er nemmere at træne samt i mange tilfælde giver udmærket resultater.
I det sidste layer angiver mængden af hidden units hvor mange mulige outputs der er, så i dette tilfælde da der arbejdes med et binært output i 0 spillet godt og 1 spillet dårligt består det af en hidden unit her bruger jeg så aktiverings funktionen sigmoid som er en funktion der giver et output mellem – 1 og 1 hvilket er godt at bruge når man ligesom mig arbejder med binær output værdi da man kan bruge det til at give en god indikation hvor stor sandsynlighed der er for det er enten 0 eller 1.
Derefter skal det neurale netværk compiles
Det gøres ved at give en loss funktion, i dette tilfælde binary_crossentropy da output er binært. binary_crossentropy er en loss funktion opstillet i keras biblioteket. Derefter skal man angive en optimizer det er en funktion som bruges til at optimere læringsprocessen for det neurale netværk. Keras har mange forskellige optimerings funktioner at vælge imellem “adam” er den mest almindelige, men man kan prøve sig frem med lidt forskellige for at finde den der passer bedst til sit eget netværk. metrics angiver ud fra hvilke parametre det neurale netværk skal vurdere hvor godt det klare sig, jeg har valgt at bruge accuracy til at måle korrektheden i modellen, man kan også bruge andre metrics som precision, recall og mange flere.
Loss giver en ide om hvor langt man er fra det rigtige resultat, hvor optimizer funktionen bruger loss værdien til at optimere modellen
Til sidst skal jeg så fitte min model det gøres ved brug af keras .fit metode på min model.
Der angives X, som består af mine features, y mine labels (outputs), batch_size som definere hvor mange datapunkter der bruges til træning af gangen. Dette er meget nyttigt især hvis man arbejder med store mængder data da det kan optage rigtigt meget memory hvis man kører alle datapunkter på en gang, en anden fordel ved brug af batch_size er også at modellen optimalisere sig efter hver batch så man på den måde hurtigere rammer en høj accuracy.. derefter angives epochs, hvilket står for mængden af gentagelse hvor den træner igennem hele datasættet.
Installere .msi filen og tryk next hele tiden og vælge “Complete” installation.
Derefter skal du inde på dit C:\ Drev og oprette en ny folder som hedder “data” og inde i den folder skal du oprette en ny folder der hedder “db”:
C:\data\db’
Derefter skal du åbne CMD og gå ind (cd) i den folder som indeholder din Mongo.EXE
F.eks C:\Program Files\MongoDB\Server\4.2\bin
Du skal derefter skrive “mongod” commanden
mongod commanden er en Mongo Daemon som er host processen for databasen. Det den gøre når du udføre kommandoen er at du siger til den “start mongoDB processen og køre den i baggrunden” derefter gemmer den data i den folder du har oprettet tidligere /data/db og køre i porten 27017.
Derefter skal du køre MongoDB shellen:
åbne ENDNU en CMD samtidig med at du har den anden kørende og så skal du ind cd ind i den
C:\Program Files\MongoDB\Server\4.2\bin
Køre commandoen “mongo”
Så mongod:
Kort for Mongo Daemon og er en baggrunds process som bliver brugt af en MongoDB server til at få ting gjort -> processen er ansvarlig for at håndtere hele MongoDB server opgaver som acceptere requests, give svar til bruger, og håndtere hukommelses krav af MongoDB.
Mongo
Er en interaktiv Javascript shell interface til MongoDB, som tilbyder en kraftig interface for system adminstrator og udvikler til at teste queries og operationer direkte med databasen.
Nu hvor vi har både serveren og shellen oppe og køre så skal vi have oprettet en Datatabase.
Oprettelse af database:
Inde i CMD shellen udføre vi kommandoen “use” som opretter en database med et specifikt navn. Derefter kan man anvende “show dbs” som viser alle oprettede databaser. Men der ingen at vise fordi i vores database har vi ingen collection der simpelt hen ikke noget data. Det skal vi have oprettet med kommandoen “db.createCollection(‘navnpåcollection’). I dette tilfælde har vi kaldt vores collection for stats. Nu kan vi udføre “show dbs” og vores database vil nu blive vist.
Nu har vi en database og en kollektion. Men vi har ikke noget data? Det vil vi gerne lave om på. Vi vil gerne indsætte et dokument/række i vores database:
i vores db instans kalder vi vores kollektion Stats og derefter kalder metoden insert() inde i metoden udfylder vi det data vi gerne vil gemme som JSON, vi kan have integers, strings, objekter osv kan gemmes.
Hvad med når vi gerne vil indsætte flere ad gangen?
Vi anvender metoden insertMany() så vi kan indsætte flere dokumenter i vores database ad gangen. Læg mærke til at vi ikke har f.eks user objekter i det nye indsatte data – det er ikke noget problem i en NOSQL da man ikke behøver at følge samme struktur for dataen da vi ikke har en striks data model vi skal følge som man gøre i almindelig SQL.
Nu hvor vi har gemt dataen i databasen vil vi gerne kunne se dem eller ihvertfald finde dem i databasen
ved anvendelse af find() metoden kan man finde alle dokumenter i ens kollektion og med metoden pretty() får vi det skrevet ud som JSON så det er pænt og læsbart
Hvis vi gerne vil lave en Query hvor vi gerne vil hente de dokumenter med specifikt data gøres det således:
Her får vi alle dokumenter hvor personer har lavet 5000 i skade. Dette ville være specielt relevant, i situationer hvor man vil finde f.eks. alle stats for en specifik user eller alle sats over folk som har ratingen ‘PlayedGood’
Man kan også sortere når man gerne vil finde dokumenter i sin database. F.eks. vil vi gerne finde alle dokumenter men hvor Kills er stigende:
det gøre vi ved at bruge sort() metoden og giver den værdien 1 for ascending og -1 for descending
Vi kan også finde ude af hvor mange dokumenter vi har i vores database ved anvendelsen af metoden count() samtidig kan man bruge limit for at begrænse hvor mange dokumenter man vil finde.
Vi kan også anvende foreach loops hvor f.eks vi vil gerne finde alle dokumenter for hver deres rating:
Nu kan vi indsætte data i vores database og vi kan udføre get operation i vores database. Så det næste man skal kunne gøre er at opdatere sin database
f.eks vil vi gerne opdatere en a dokumenterne hvor spilleren faktisk har spillet dårligt det gøre vi således
ved brug af update metoden kan man opdatere på et specifikt dokument ved at give ojbect id’et som den får når man opretter et dokument. Derefter anvender man javascript $set til at ændre på specfikke værdier. Hvis man ikke bruger $set så fjerner den alt indhold fra dokumentet og indsætter kun det du har ændret. Og når man anvender upsert: true så vil den oprette et nyt dokument, hvis der ikke allerede findes et dokument med det givne id.
Man kan også incrementer en værdi i et dokument som kan ses på overstående billede ved at anvende $inc.
Man kan også ændre på selve fieldsene i et dokument som f.eks fra Kills til Dræbte ved at anvende $rename javascript funktionen.
Nu kan vi opdater vores database så mangler vi en sidste funktionalitet og det er at kunne slette i sin database
dette sletter et dokument med et specifikt id.
endnu en interessant funktion med mongoDB er at man nemt kan udføre relationer i dokumenter. F.eks. Kan man lave en EN-TIL-MANGE relation i det samme dokument.
Som vi kan se her så har vi i vores collection indsættes et dokument der indeholder et HOLD i league of legends computerspil. Vi kan se at en kamp har en-til-mange relation til brugere dvs at et team har flere brugere men en bruger har kun et team. I mongoDB kaldes det ikke for en relation men hedder embedded document pattern.
Vi kan nu bruge Javascript funktionen elemMatch til at finde teams med brugeren hvis navn er Thejokerd3.
Som det kan ses ud fra billedet kommer det team op som vi lige har lagt ind i vores database.
Noget af det smarte ved Document Database er at det er meget nemt og fleksibelt at indeksere. Vi kan selv oprette et indeks som vi vil kunne indeksere efter, i dette eksempel vil vi arbejde med “Color” så vi kan søge efter farven på holdet. Det gør vi ved at kører en createIndex funktion hvor vi giver hvilket field vi vil indeksere efter, samt hvilket format. I dette tilfælde tekst
Her kan vi så se at det er lykkedes os at tilføje vores indeks da der før var kun 1 indeks, hvilket var vores id, hvor der nu er 2 indekser.
Nu kan vil vi så søge efter alle de teams mede “color” som er ‘blue’. Det gør vi ved brug af det index vi lige har lavet, samt javascript funktionen $search hvor vi søger efter alle de dokumenter der har blue i vores text indekser som består af fielded color.
Derefter kan vi bruge Javascript funktionen $gte til at finde alle dokumenter hvor kills er højere eller lig med 15, hvis man kun vil finde værdier der er højere kan man bruge $gt, og ligeledes hvis man vil finde værdier der er lavere kan man bruge henholdsvis $lte eller $lt
Vi vælger at arbejde med Document Database. Grunden til at vi har valgt document database skyldes at den komplementære det vi gerne vil opnå med vores database rigtigt godt. Den gør det nemt at hente alle dokumenter i kollektionen og lave analyse over dem, hvilket er utroligt vigtigt i Machine Learning, da det er nødvendigt til at udvikle ens model, og vælge hvilken algoritme man skal arbejde med. Den har mere eller mindre alle de samme perks som de andre NoSQL databaser har, i og med at den er skalerbar og fleksibel. Den er nem at arbejde med gennem andre programmer da dokumenterne bliver gemt i JSON format.
Hvorfor vælger vi ikke:
Graph SQL -> Grunden til vi ikkke vælger graph sql er fordi at vores datasæts datapunkter ikke har nogle direkte relationer til hinanden. Vi har ikke brug for at struktuere med relations da det ikke er nødvendigt, fordi vi har med rå data at gøre.
Column oriented database -> god til at indexe data i store datasæt, men ikke god til at bygge videre på datasættet eller god til brug hele datasættet på en gang. God til at arbejde i hele kolonner.
Key value -> gode til at finde specifikke værdier i et datapunkt ved anvendelsen af key strukturen. Hvilket gøre det hurtigt at indexere igennem hvis man vil finde en specifik værdi i et datapunkt. Den er dog dårlig til at finde hele kollektioner. De eneste queries som er effektiv er one-row-at-a-time queries. Og ikke god når data modeller vokser i kompleksitet.
Når du har hentet redis skal du inde i folderen -> program files -> Redis -> redis server.exe
Derefter skal du åbne Program files -> Redis -> Redis-cli.exe
Man arbejder hele tiden i Command Prompt
Så skriver du commandoen PING og får du PONG tilbage betyder det at serveren fungere og der er forbindelse og du kan nu påbegynde din rejse i Redis Key value database.