aflevere litteratur liste hvis man har i portefølje så det fint
udsøge de dele du skal bruge i forhold til litteratur liste
video med sin app og laver en overfladisk det skal man lade være med
her ligger der noget kompleksitet
begge emner skal inddrages
hvad i har lært hvad i har lavet og hvordan i er kommet frem til det.
Powerpoint:
Link til diverse sider: Portefolio Github Andre links? Læringsplan som er inde på min portefolio Som viser viden, kompetencer og færdigheder ETC Point Produkt video Video der viser det man har lavet (måske også side projekter)
Dette opslag omhandler et sideprojekt jeg har lavet i Machine Learning med algoritmen af neurale netværk. Sideprojektet omdrejer sig om spillet League of legends som jeg er stor fan af. Det er et spil jeg har brugt meget tid på at spille.
Jeg fandte det derfor interessant at lave et projekt omkring det. Derfor har jeg udviklet en beregner som skal forudse om man har spillet dårligt eller spillet godt. Det er et strategisk spil hvor man spiller 5 mod 5 og omhandler om at dræbe hinanden og ødelægge hinandens baser.
Det neurale netværk algoritme skal kunne forudse om man har spillet dårligt eller spillet godt ved at pumpe data ind:
Antal dræbte
Antal gange man har været død
Antal assisterende dræbte
Antal Wards placeret
Antal Pinkwards placeret
Antal wards ødelagte
Hvor meget skade man har lavet
Hvor mange CS (Creep store) man har
Udefra de værdier skal algoritmen fortælle om man har klaret det godt eller ej.
Der er blevet lavet en neural netværk algoritme. En kunstige neural netværk bentter matematiske værktøjer til at implementere algoritmen. Det neurale netværk er inspieret af den menneskelig hjerne og derfor navnet.
Det neurale netværk der anvendes er indenfor paradigmet for Supervised Learning som er et princip i machine learning som man kan anvende når man har med Labeled data at gøre. Under det princip har vi valgt tilgangen for classification. Classification omhandler at man klassificere sit output enten boolske eller lignende (dvs enten ja/nej, true/false, 0/1) der er dog blevet anvendt et karakter lignende skema hvor man får en karakter på hvor godt man har spillet og derfor klassificere det således.
Som vi kan se på ovenstående billede har vi input layer det er det data der bliver pumpet ind i algoritmen – i dette tilfælde af det spillets data. Det kaldes også input dimensions som i teorien bare er de features som datasættet har.
Så har vi hidden layer som ligger imellem input og output noderne, og som indeholder nogle BIAS værdier som laver en udregning og udefra uderegninger aktivere den noget der hedder (activiation function) og producere et output.
Så har vi vores output layer som er den endelig klassificering altså forudsigelsen.
Pilene kaldes for weights parameters som repræsentere værdier som bliver brugt til styrken i forbindelsen mellem neuronerne. Det var meget abstrakt forklaret – men jeg håber i forstår pointen.
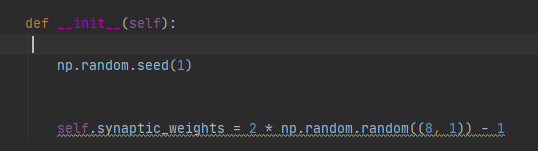
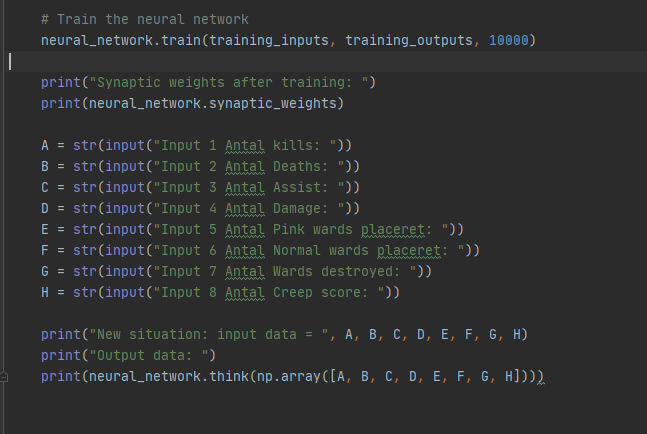
I starten af projektet har vi følgendes implementering vi tager det linje for linje
Numpy biblioteket indeholder stor samling af matematiske funktioner på højt niveau og understøtter multidimensionelle arrays og matrixer. Vi anvender det i hele projektet.
Vi starter med at definere en funktion og denne funktion tager brug af numpy biblioteket. Vi køre linjen random seed som skal give os de samme random værdier til vores bias hidden layer så vi hele tiden har samme random værdier hver gang. Derefter Sætter vi vores synaptics weights til at være 8×1 matrix da vi har 8 features. med værdierne mellem -1 til 1. Så vi hele tiden arbejder i små værdier.
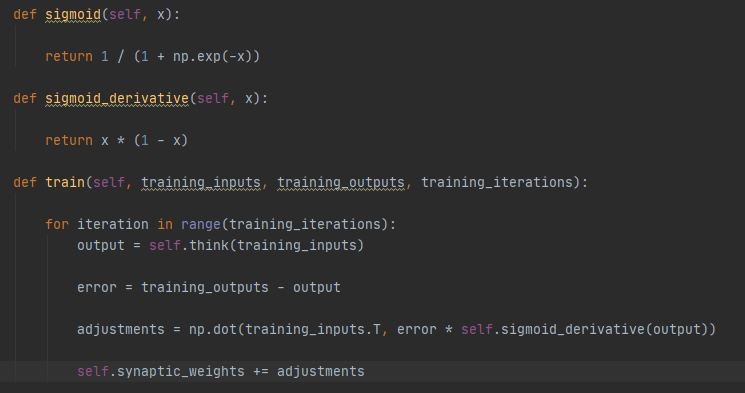
Så definere vi en sigmoid funktion. Sigmoid funktionen anvendes til at beslutte om en neuron skal aktiveres eller ej. Om informationen som det neurale netværk får er relevant for aktivationen af et neural netværk eller ej.
Vi definere også en sigmod derivative funktion som bliver brugt til at justere vores synaptic weights efter hver iteration.
Så definere vi en trænings funktion. Som får noget træningsinput (som er feature værdier i vores data) nogle træningsoutputs(som er outputted i vores datasæt) og hvor mange iterationer vi gerne vil igennem. Funktionens body indeholder et for each loop som siger at for hver iteration vi har i vores training_iterations vil vi gerne kalde metoden think som er i selve klassen og giver den trænings input som parameter. Derefter finder vi resultat af fejl ved at trække træningsoutput fra det beregenede output. Derefter justere vi vores synaptic weights ved at inkludere vores trænings input, fejl resultat og vores sigmoid deritative funktion.
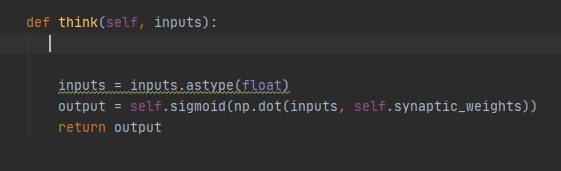
Som vi kan se på ovenstående function er vores think function som tager imod et input og caster det til en float. Det er input brugeren indtaster i consolen. Vi får så returneret et output ved brug af sigmoid funktionen som tager imod inputsne og de predefinered synaptic weigthts.
np.dot hvis det ene array er et multidimensional array og b er et 1-D array som det er i vores tilfælde er det summen af produktet over den sidste axe af a og b. Derefter returnere vi outputtet.
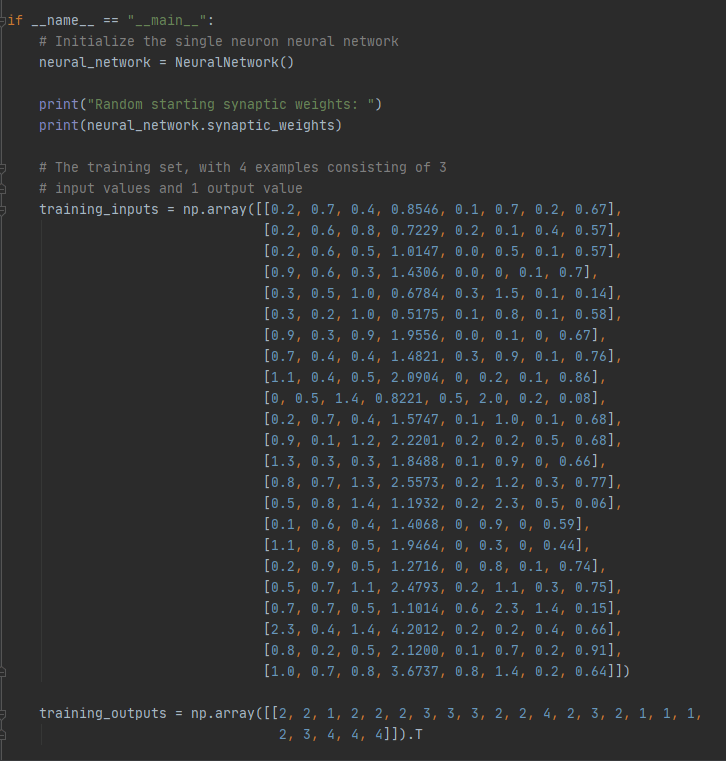
Ovenstående billede er vores trainings input. Vi anvender numpys biblioteket igen til at lave det om til et numpy array grunden til vi bruger et numpy array er fordi at man så har adgang til en masse vector og matrix operationer samt er numpy arrays meget mere effektiv i runtime.
Værdierne er i arrayet er kronologisk rækkefølge: Antal dræbte, antal gange man har været død, antal assist, mængde af damage, antal wards placeret, antal pinkwards placeret, antal wards ødelagte og CS(creep store)
så har vi vores training output som indeholder karakteren i tal for 1 er det bedste og 4 er det laveste. Vi derefter laver det til et np array hvor vi transposer det således at værdierne er proportional.
Som det sidste kodestykke – viser ovenstående billede hvordan vi kalder vores train metoder som vi fik defineret tidligere, og giver den vores training inputs, training outputs og trainings iteration altså hvor mange gange vi vil itere igennem. Derefter printer vi synaptic weights efter at vi har trænet vores model.
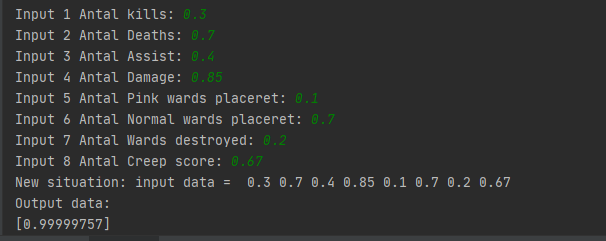
Derefter udskriver vi til consollen som venter på at modtage input fra brugeren. Når brugeren har indtastet dataen vil vi smide dem ind som parameter inde i vores think metode som vi defineret før. Den går ind og anvender sigmoid funktionen med synaptics weight og udregner en beregning på korrekthed.
På ovenstående billede kan vi se resultatet vi får 99% korrekthed med at finde en karaktere til spilleren efter at have indtastet dataen. Det er meget præcist, fordi vi har trænet modellen med mange iterationer.
Refleksion
Under udførelsen af dette projekt stødte vi på nogle problemer i forhold til hvor store tallene var i vores data. da vi endte med weights der havde så mange decimaler at det ikke var muligt at regne med dem f.eks. 3.6234474e-20, derfor var vi nødt til at gå ind og mindske størrelsen på tallene for vores inputs. Først prøvede vi med at reducere, så der kun var tal mellem 40 – 0, men det virkede stadig ikke, så vi gik ind og dividerede det hele med 10, så vi endte med tal mellem 4 og 0, der lykkedes det os endeligt at få det til at fungere. Dette kan være problematisk da vi ikke har ændret noget i koden, kun i de inputs vi arbejder med, så hvis en person ville bruge vores pogram og taster inputs fra spillet uden at vide hvilket format tallene skal omregnes til, vil det fejle og personen vil få et forkert resultat ud.
Fremvisning af det man havde lavet i de sidste 2 uger – mig og daniel præsenterede vores proof of concept samt data forbehandling og no sql cloud løsning
Snakkede om at mødes noget oftere med gruppe
Fokusere på at bredde sine emner frem for at fordybe sig da man ikke får så mange point i det
sådan hænger det sammen når man arbjeujder på den måde med hensyn til læring. At det bliver mere kompleks mere over tiden
tage udgangspunkt i vinduer kode når man skal snakke om det tage udgangspunkt i praksis hop direkt i det
tager den fra den anden ende så vi kommer igennem fra komepetencer og hen mod viden
bruger det aktivt frem for at snakke om det. Herunder refleksion -> snakke mod teori bruge den praktisk Tage udgangspunkt i jeres produkt konkrete ting og forklare udeaf
Kigge på ANALYTICS Vidhya artikler omkring time series -> snakkede lidt omkring det problem jeg havde i projektet hvor vi arbejder med tidspunkter på hvornår der holdes pause
Når vi ikke har rigtige data så ved vi ikke hvor præcis modellen kan blive.
Kigge på classification altså holder han pause eller ikke
Timeseries vs classification
Drage konklusioner af sin data -> er det virkeligheden?
Specifikke læringsmål og læringsplan – 4.Iteration
Mål
Teknik/Værktøj
Kriterier
Evaluering
Anvende en databasegrænseflade til et Machine Learnings projekt
Jeg vil gerne finde ude af hvordan jeg opretter en connection til MongoDB:
– Brug af erfagruppen til at diskutere måder på at kunne oprette en forbindelse.
– Søg efter viden på Youtube, Forums, Google og andre litteratur.
Kan jeg redegøre for hvordan jeg har implementeret min databasegrænseglade til min ERFA Gruppe og min produktgruppe samt diskutere relevante emner deromkring.
Jeg kunne repræsentere det for min erfa gruppe og fremlagde hvordan jeg fik det integerede ind i et projekt jeg havde lavet i machine learning. Jeg kunne også indsætte et specifikt datasæt hvilket gjord det effektivt at bruge når jeg skulle trække data fra databasen ind til mit projekt.
Jeg vil gerne finde ude af hvordan jeg importere og eksportere data til og fra min databasegrænseflade:
– Brug af erfagruppen til at diskutere måder at gøre det på
– Anvendelse af Linkedin/Google/Youtube
– Netværk / venner / bekendte
Arbejde med et datasæt som er relevant for vores Produkt
Jeg inspecter datasættet, for at finde ude af om der er nogle problematikker som skal løses før vi kan udføre vores machine learnings algoritme:
– Jeg anvender pandas biblioteket til at læse datasættet
– Jeg anvender Python Programmering til at udskrive et læsbart datasæt
– Bruger linkedin/Youtube for at finde video omkring emnet
– Anvender litteratur herunder Bøger omkring emnet
Kan jeg fremvise mit datasæt for min erfa gruppe?
Kan jeg redegøre for de ædnringer der er blevet foretaget undervejs?
efter snak med produktvejlednings mødre ente jeg med ændre kurs og nedprioritere denne del så jeg kunne lægge vægt på andre side projekter i nosql og i machine learning. Jeg fik også dermed snakket i erfa gruppen angående at anvende andre måder at datavisualisere.
Jeg undersøger missing values, non-numerical features samt overflødiske features for modellen:
– Jeg anvender Numpy biblioteket til at fikse de steder hvor der er missing values
– Jeg anvender scikitlearn Biblioteket til at ændre non-numerical features til numerical features
– Jeg anvender pandas biblioteket til at fjerne ikke-relevante features
– Jeg anvender google for at finde artikler omkring emnet
– Bruger netværk herunder ERFA grupper/Bekendte
– Bruger linkedin/Youtube for at finde video omkring emnet
Generelle læringsmål
Viden – Den studerende har viden om
Det/de valgte emners teori og praksis
Det/de valgte emners relevans i forhold til IT-fagets teori og praksis
Færdigheder – Den studerende kan
Udvælge, beskrive og foretage litteratursøgning af en selvvalgt it-faglig pro-blemstilling
Diskutere samfundsmæssige aspekter knyttet til det/de valgte emner
Vurdere problemstillinger og opstille løsningsmuligheder i forhold til det/de valgte emner
Formidle centrale resultater
Kompetencer – Den studerende kan
Selvstændigt sætte sig ind i nye emner inden for fagområdets teori og/eller praksis
Perspektivere og relatere det/de valgte emner i forhold til uddannelsens øv-rige emneområder
Nødvendigheden / vigtigheden i at arbejde sammen, arrangere nogle dage f.eks mandag, onsdag og fredag som gruppe online og arbejde sammen, planlæg og snakke med hinanden og få holdt hinanden op på det. Så det giver mening
Fremlagde vores portfolio og lidt at de sideprojekter vi havde lavet.
Ricki viste sine sideprojekter i datavisualisering webudvikling flask
Daniel viste sit sideprojekt i datacamp og sin portfolio
Denne post indeholder mit sideprojekt for Supervised Learning (Machine Learning) som jeg har taget i Datacamp. Den indeholder et projekt som omhandler at lave forudsigelser på Kredit Kort godkendelse.
Dette er link til mit github som indeholder både datasættet og min Python Fil.
Jeg har brugt PyCharm fra Jetbrains – som er et super fint IDE til at lave Python projekter i. Dermed er biblioteker som Numpy, Pandas og sklearn blevet installeret til mit projekt.
Skulle fremvise det type af NOSQL der findes i dette tilfælde havde jeg NOSQL GRAPH Databaser -> lagt tutorial oppe på min portefølje
Snakke lidt om de andre NOSQL typer som de andre havde om
Kigge på til næste gang hvordan man kan anvende document database i et Machine Learnings projekt og prøv og se om man kan få en integration mellem de to projekter database og machinelearning
Machine Learning
Jeg havde ligget syg så jeg snakkede om hvorvidt jeg skulle catch up på det jeg har været bagud med.
Hvad jeg kan gøre for at indhente -> færdiggøre credit card approval projektet i Datacamp
Arbejde med et datasæt som er relevant og som peger lidt mere mod projektet -> herunder snakke med Ricki som simon også snakkede med